Why speed read this, you ask?
Learn how AI can plow through an inbox at superhuman speeds. Let an AI summarize and help you focus. That’s what I need.

[ed. This is my first joint blog post with @chrissmattmann, a fellow AI nerd who happens to work in the CTO office of NASA JPL. We’re trying to figure out what “I” and “we” means in a co-authored post, so bear with us. Now, onto the story.]
The Full Inbox Problem
My inbox is full. No, like really full. Really, really, really full.
There are so many amazing AI research papers, tantalizing Medium posts, emails from coworkers, links from Slack rooms and our growing pile of unread magazines. Then there’s that addictive, hilarious feed from TikTok (thank you, quarantine, for that one), Instagram stories, YouTube videos, and NetFlix shows. Help!
Turns out, I’m not alone.
When Covid-19 hit, I joined the bandwagon of Google volunteers eager to help. My friends at NASA also stepped in, from making ventilators, respirators and masks to helping with data. Soon I bumped into teams from the CDC, several US states, the MITRE Covid Coalition, and a few top banks.

Banks wanted to process 70 million articles written about Covid-19 to model the impending economic shock wave. The CDC had over 9,000 inbound emails with unread, detailed medical papers and commentary. My inbox problems were Lilliputian by comparison. Heck, the White House and the Office of Science and Technology Policy (OSTP) even got involved, working with the the Kaggle team at Google, the Gates Foundation and others to make 40,000 publications available for AI researchers to mine.
Now we’re really going to need Google scale help.
Bert to the Rescue
Google recently installed an AI technology called Bert from GoogleAI to help with search. Bert reads superhuman fast and helps Google understand our searches. We use Bert-like inferences over one billion times a second. That can help us read fast! Bert uses tensors, like I discussed in last week’s post. I mean last quarter’s. Oh, geez, has it really been that long? With Chris here and other various elements of guilt that we’ll cover later, the two of us will minimize future lag in the posts.

Bert radically altered how scientists model human language. Before Bert, most used fancy versions of what we all learned in grammar school. We work with words. We’d label some of their parts of speech nouns, others as verbs, and some as adjectives. We’d “parse” them into grammar trees like our teacher showed us, understanding how to put together sentences.
Bert threw that out.
Instead, Bert’s based on neuroscience. Studies at Berkeley College have shown that similar words often activate the same physical location in our brains. I encourage you to visit their site; peeking inside our brains is fun. More links for your full inbox!
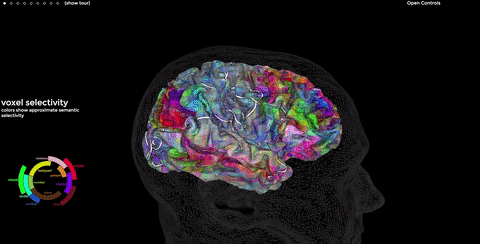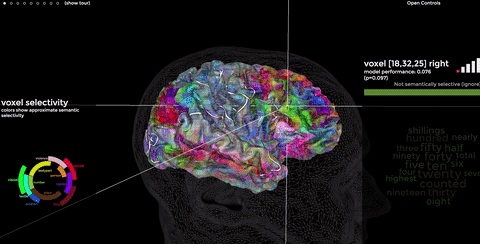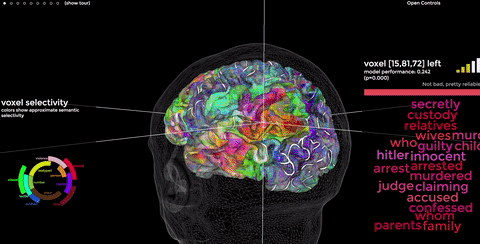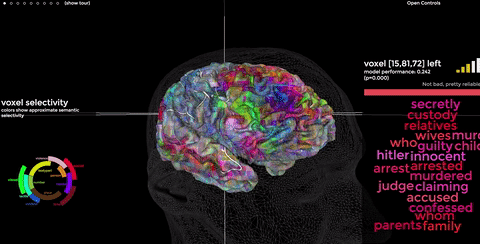
As you recall, we can write down the charge in every brain neuron as a tensor. Bert “simply” turns our language into tensors, uses math to model the shapes it sees, then turns those shapes back into language, like our brains do. Well, sorta.
How Bert Works
The first thing Bert does is collect a sample of human language for training. Hey, it’s Google, and we grabbed Wikipedia pages to train Bert. Like… all of it. The whole Internet, a nice benefit to working at Google.
Next, Bert first lists all one billion unique words from top to bottom and gives them a number:
1. My
2. Lovely
3. Inbox
4. Is
5. Replete
6. …
The list gets super long. So, Bert researchers broke the list of a billion words into a smaller list of 60,000 common words and word parts, like this:
1. My
2. Love
3. ##ly
4. Inbox
5. Is
6. Re
7. ##plete
The “##” means it’s a word suffix. Everything else is a frequent word or prefix. Now, when you feed a word into Bert, the first thing he does is lookup word parts in the list, then list out the numbers he found, in order.
One Hot Encodings
“My Inbox is replete” becomes the sequence 1, 4, 5, 6, 7. But Bert
wants tensors. He first makes a tensor with 60,000 elements, one for
each word part in his list. That’s still tiny compared to our brains!
Next, he puts a full charge “1” whenever we use a word, and an empty
charge of “0” everywhere else.
This is called a one-hot encoding. A “hot” neuron is 1, a “not” is 0. Here’s
ours, which is 60,000 elements wide, mainly 0’s with a few 1’s up front.
[1, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0 ,0, 0, 0, 0, 0, 0, 0, 0, 0, …, 0]
Know what’s neat? We can turn a solitary word, a full sentence, or an entire document into a single tensor… of the same size. Moby Dick? 60,000. The word “rose”? 60,000. One-hot was inspired by how we think. We recall large books we’ve read, or even the smell of a rose, as a tensor. One-hot is a crude way to represent words we’ve seen.
We can do better.
While small compared to our brains, one-hot encodings are unwieldy for computers. They also don’t group together well.
Bert arranges its internal graph in twenty-four layers, inspired by layering in our own brain. Each layer pays attention to different parts of a tensor, at different times, to understand text better. For example, paying attention to the title and first paragraph of news is often a good trick for scanning a newspaper. Similarly, reading the abstract and conclusions in a research paper, while skimming the insides, gives you a sense for what’s inside. This is how Bert speed reads.
Bert represents its “thought” for each layer as…. 32 floating point numbers. A word in memory. If you stack all these up–which we can do, we’re just folding tensors–we get 768 numbers (24*32).
So now Bert wants to reason with 768-dimensional tensors. How do we cram a one-hot tensor of 60,000 dimensions into a paltry 768? You guessed it, we build a graph. AI has come up with three ways to do this, all within the last five years. Like Goldilocks, Bert chose the third.
-
Predicting the Next Word. Bert researchers first tried building a graph that would guess the next word in a sentence. The input tensor would put two words side-by-side, for 120,000 values. The output tensor would be the next word, also 60,000 values. Bert squeezed tensors through an hourglass shaped graph, where the narrow part could be 768-elements wide. That tight layer in the middle of the graph would “embed” the information contained within the larger, 60,000 dimensional tensor. Neat trick. The graph distills information into a tighter, more easily handled representation. Still, this was… meh, soooooo 2015.
-
Predicting the Middle Word. Bert tried an alternate approach, where the input was also two words, but his graph would guess the middle word. The remarkable innovation here was adding parts of the graph to pay attention to words on the left or right. Word meanings are more contextual, so this was a big step up from guessing the next word. For example, “bank” means one thing in “I deposited cash at the bank” and something else entirely in “the Hudson River bank is lovely in the summer.” Attention matters. Now we’re 2017-era, back when you could go out and enjoy those lovely summers after finishing your coding in a nice restaurant. We’ll get back there. And Bert will help us.
-
Playing Mad Libs. The real breakthrough came when Bert decided to play Mad Libs in 2018. In this classic game, you take a paragraph of text and blank out a few nouns, verbs and modifiers. You ask friends to guess the blanks, reading out the result, much to the delight at dinner parties. By playing billions of Mad Libs games with Wikipedia, Bert was able to compress the “contextual meaning” of words into 768 values better than anyone had done before.
Armed with its compact understanding of text, Bert applies his neural math skills to all sorts of cool use cases. Delineating between “banks”? That’s child’s play for Bert. How about which emails in my tranche of 60,000 have a potential breakthrough understanding of Covid-19’s transmissibility? Or which of the 1000s of CDC regulations should be streamlined in order to get out personal protective equipment (PPE) into emergency use and who in particular is the key regulatory person and associated organization to contact? Bert can easily tell us because Bert already knows.
In our next post we’ll delve into how Bert knows by explaining how he reads. Like really fast reading. There are dozens, if not hundreds, of improvements on Bert from the research community. We’ll discuss a few of our favorites, too.
Please follow us to see what else we have coming!
Enjoy,