Welcome to the first edition of Memeified AI!
Memeifieid AI summarizes important works in the AI field as memes and tweets, so that busy people can get a sense of what’s inside. This edition translates Andrew Ng’s wonderful, free, online book of “Machine Learning Yearning” into fun memes, tweets, and isms. Whatever an ism, is.
The titles shown in bold are straight from Andrew’s book. The memes and tweetish summaries are mine, so any errors are clearly me just thinking unclearly. For the curious, I also provide a 20-minute talk with Q&A if your group is into that sort of thing.
Machine Learning Yearning
written by Andrew Ng, memeified by me
0 Unofficial Forward
Before we get started, I thought I’d share a personal story about how these memefieid posts came about, so you can understand the source of my madness.
I’ve long been a fan of Carl Sagan, Richard Feynamnn, and Neil de Grasse Tyson. They’re superb communicators who transform the most complex mathematics, physics and science into fun, approachable lectures, speeches, and sound-bites. I grew up with Carl’s Cosmos on PBS, studied Richard in college and last week, and am in awe of Neil.
A few weeks ago I sat down with my friend Paul Magnone, who I’ve known for quite a long time. He asked me what Feynmann might have done today, were he to rebuild his famous lectures on science. How might he apply his infamous wit and sense of humor to heady, complex subjects? Surely he’d give lectures on YouTube. But what else?
We had the benefit (or impairment) of a nice bottle of wine, and one of us blurted out “Memes and Tweets.” At first we laughed. How absurd would that be? These subjects are complex, far more than can fit in a small form factor.
Then we got to talking. How much do we really retain from a lecture, weeks or months after we’ve participated? Even professional PR leaders drive us to focus on sound-bites. Could we actually extract something fun, lighthearted but meaningful from such dense material? The wine and friendship bravado gave us (over) confidence.
“OK, you first,” said Paul. Smart. He’d wait and see.
So that’s how I spent an August vacation back East in 2019. You’re seeing the inaugural launch of Memeified AI. They’ll get better. Maybe. I hope you like it, and have as much fun viewing it as I did putting it together.
1. Why Machine Learning Strategy
This book will help you spot clues in your machine learning system, saving you months to years of development time.

2. How to use this book to help your team
Like a tip? Share the 1-2 pages of text with your colleagues to spread the word.

3. Prerequisites and Notation
You need to know a little about machine learning (ML), supervised learning, and deep learning to get the most out of this book.

4 Scale drives machine learning progress
You obtain the best performance from neural network ML systems when you train a very large network and have a huge amount of data.

5 Your development and test sets
The “training set” of data trains your network, the “dev set” of data is then used to tune parameters, and the “test set” evaluates performance. The dev and test sets direct your team toward important changes in the ML system.

6 Your dev and test sets should come from the same distribution
Don’t train your network on one set of data and expect it to work well on other types of data. Be realistic.

7 How large do the dev/test sets need to be?
The more accuracy you need, the more data you need. I derived a handy calculation for you.

8 Establish a single-number evaluation metric for your team to optimize
Too many cooks spoil the broth. If you have several, assign weights in an ensemble or use a geometric mean (e.g. the F1 scores). Lower values must be better.

9 Optimizing and satisficing metrics
If you must, you can use two metrics. One specifies a minimal criteria that satisfies the business need. A second allows you to optimize performance.

10 Having a dev set and metric speeds up iterations
A dev set and a single metric let you iterate faster, keeping your team focused.

11 When to change dev/test sets and metrics
If you realize your initial dev set and metrics weren’t right, change them, ensuring they reflect realistic scenarios.

12 Takeaways: Setting up development and test sets
The ML iteration cycle involves selecting an idea, writing some code, evaluating the dev set with your metric, and repeating. Most initial ideas flounder, so don’t be discouraged. Its all part of the ritual.

13 Build your first system quickly, then iterate
Don’t over-engineer your ML system. Get something started, quickly. Iteration wins over deliberation.

14 Error analysis: Look at dev set examples to evaluate ideas
Be analytical and systematic in ML. Look at your data failures, categorize them in a spreadsheet, see what you have, and evaluate objectively.

15 Evaluating multiple ideas in parallel during error analysis
Turn your ideas for improving the ML system into columns of a spreadsheet, then check off which of the failures the idea will address. Evaluate objectively.

16 Cleaning up mislabeled dev and test set examples
Only fix mislabeled data when this “flaw” is larger than other flaws you’ve seen in your data. For example, if its just a 1% problem, and you’ve got a 20% error, focus elsewhere.

17 If you have a large dev set, split it into two subsets, only one of which you look at
Create an “eyeball” subset of your large dev set which you’ll review manually, applying human intuition to guide ML development. The rest is called the “blackbox” dev set.

18 How big should the Eyeball and Blackbox dev sets be?
Eyeballs tire out after about 1,000 examples. Blackbox should be big.

19 Takeaways: Basic error analysis
Use spreadsheets and be analytical when tuning ML systems.

20 Bias and Variance: The two big sources of error
An easy way to remember these terms is that bias errors occur with your training set, variance errors occur with your dev and test set.

21 Examples of Bias and Variance
Variance is the additional error in your dev and test sets, above and beyond the error in your training set.

22 Comparing to the optimal error rate
Sometimes its impossible to get error below a threshold, such as in speech recognition problems with very noisy backgrounds where humans struggle to hear. This is called the “unavoidable bias” error in your data set.

23 Addressing Bias and Variance
When you have high training error rates, increase the size of your model to capture more information. When variance is high, add more data to your training set to fix those errors.

24 Bias vs. Variance tradeoff
Bigger models improve bias, screw up variance. Regularization can improve variance, but screw up bias. Ah, life.

25 Techniques for reducing avoidable bias
Futz with your model architecture and input features to improve bias.

26 Error analysis on the training set
Classify your training errors as columns in a spreadsheet, then check off each column for each data element your ML system failed to analyze.

27 Techniques for reducing variance
Add more training data, introduce regularization (smoothing out weight distributions), stop your training earlier, reduce input features, or use a smaller model to reduce variance.

28 Diagnosing bias and variance: Learning curves
Train your model on training sets of increasing size while ensuring they each are a representative sample of the real world. Evaluate metric on the dev set. Plot results.
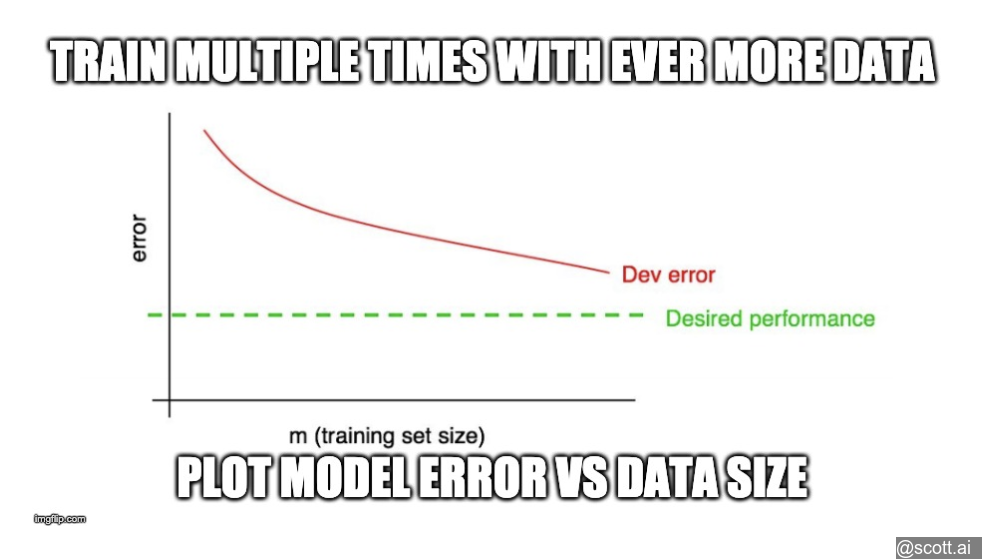
29 Plotting training error
Add another curve showing metric performance on the test set, as you increase training set size.
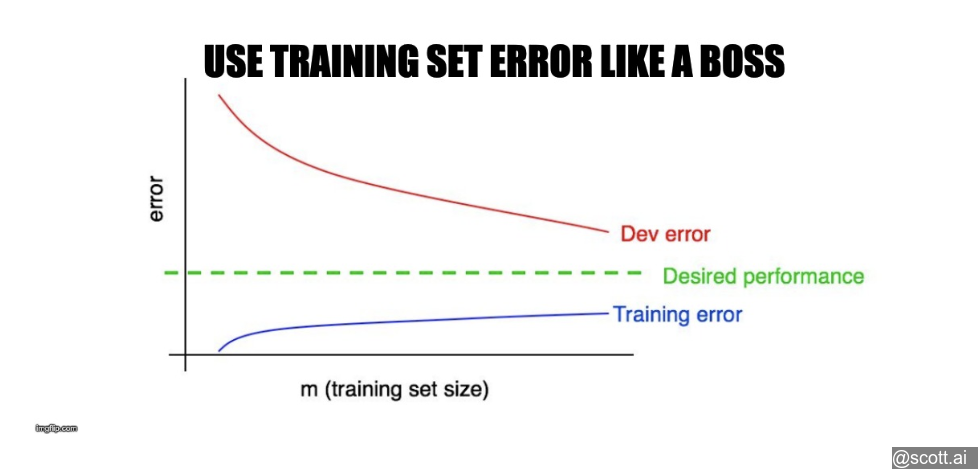
30 Interpreting learning curves: High bias
If your dev metric plateaus above ideal performance, you have high bias.
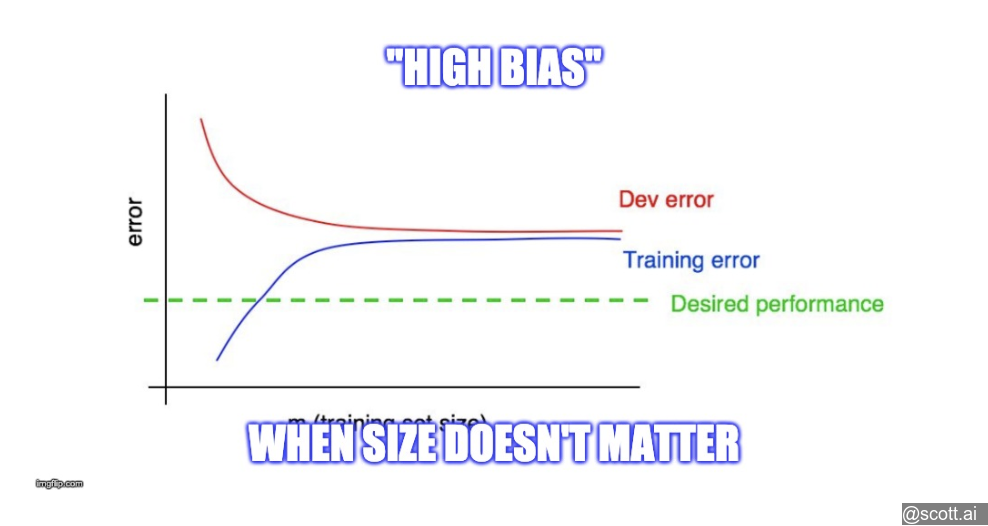
31 Interpreting learning curves: Other cases
If your test metric is worse than ideal performance, you have high bias.
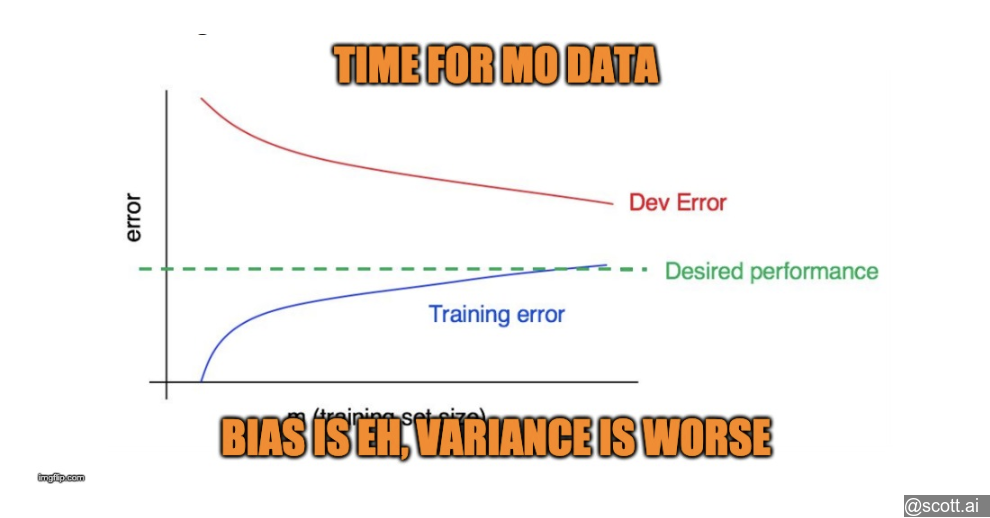
32 Plotting learning curves
If your test metric is good but dev metric is worse and hasn’t plateaued, you have high variance.

33 Why we compare to human-level performance
Tasks that humans do well enable us to specify human-level performance, which gives us a clear goal and insights into failure along the way.

34 How to define human-level performance
Be like Andrej, take the test yourself if nobody’s done it before. For all other cases, aim for the stars and use the human record performance.

35 Surpassing human-level performance
Use error analysis and introduce data to train your model, just like they do at Tesla.

36 When you should train and test on different distributions
Um, never. That’s an old school thought.

37 How to decide whether to use all your data
Never use irrelevant data, or data you won’t encounter in practice.

38 How to decide whether to include inconsistent data
Never use data with irrelevant context. For example, when predicting NYC real estate values, don’t train on real estate from Detroit.

39 Weighting data
Apply a weighting factor to errors from synthetic data, so that errors from real data count more.

40 Generalizing from the training set to the dev set
If your dev set errors are high, but errors on unseen distributions drawn from your test set are low, you have data mismatch.

41 Identifying Bias, Variance, and Data Mismatch Errors
“Avoidable bias” means your model is making mistakes when humans would not. Your sources of error are (1) unavoidable bias, (2) avoidable bias, (3) variance, and (4) data mismatch.

42 Addressing data mismatch
Try to understand why your dev set doesn’t represent the same distribution as your training set. Once you do, realign the data sets and add more data where needed to better represent the real world.

43 Artificial data synthesis
Synthetic data may contain hidden patterns not visible to humans, but that can create models with artificially good performance. Be careful, blend synthetic data with real data.

44 The Optimization Verification test
Many models output a sequence of values. Search is the task of finding this sequence that maximizes model performance. Scoring is the task of evaluating a single sequence.

45 General form of Optimization Verification test
Test the score of the correct output you expect from sequence models. If this is worse than the output of your model, you have a search problem. Otherwise its a scoring problem.

46 Reinforcement learning example
Always ensure that your reward function in RL actually prefers optimal paths, tested by evaluating an optimal human performance.

47 The rise of end-to-end learning
In lieu of end-to-end deep learning with a giant model, try pipelines of simpler, understandable, explainable tasks.

48 More end-to-end learning examples
Self-driving cars and speech translation are recent examples of (people trying to use) end-to-end deep learning systems.

49 Pros and cons of end-to-end learning
End-to-end systems work best with lots of labeled data, from input to output. Without it, data pipelines and features are your friend.

50 Choosing pipeline components: Data availability
Design your pipeline components around available data, e.g., one to detect cars, another to detect pedestrians, and a third to plan a path forward.

51 Choosing pipeline components: Task simplicity
Simple is as simple does. Don’t over-think things, divide and conquer ML pipelines, keep parts simple, then iterate.

52 Directly learning rich outputs
With the right input and output pairs, deep learning can produce many exciting, rich output sequences. Examples include image captioning, speech recognition, text to human-like speech, and question answering systems.

53 Error analysis by parts
Apply error analysis (error category vs. data spreadsheets) to each part of an ML pipeline.

54 Attributing error to one part
Correct erroneous inputs before testing an ML pipeline component. This avoids cascading errors and helps isolate root causes of failure.

55 General case of error attribution
Draw your ML pipeline as a directed acyclic graph, then walk it once to get a linear order of pipeline parts for error analysis.

56 Error analysis by parts and comparison to human-level performance
Focus first on pipeline components that haven’t reached human-level performance. Premature optimization is the root of all evil (or, at least some frustration).

57 Spotting a flawed ML pipeline
When all your parts are working at a human level or above, and the model is still failing, your pipeline design is flawed. Change it.

58 Building a superhero team - Get your teammates to read this
Share the joy of this blog post and Andrew’s wonderful book with your own, superhero ML team!
